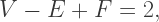In my last post, I talked about a textbook I had written to use in a course which, among other things, introduced students to a non-Euclidean geometry — spherical geometry. And while the primary purpose of the text was for teaching a college-level course, the actual content of the text had a different origin.
As I have mentioned previously, I got interested in polyhedra during graduate school, and was very fond of taking books about polyhedron models out of our mathematics library at Carnegie Mellon. It was easy enough to photocopy the nets provided, or use the numerical data to construct nets on my own.
But what was missing for me, a mathematician-in-training, was a more rigorous discussion of these intriguing models. For example, Wenninger’s Polyhedron Models contains many nets with some idea of how to construct them from a more general geometric point of view, but few details. And his Spherical Models contains many tables of data of angular measures to three decimal places, but many derivations are missing. Other books included metrical data such as the measures of dihedral and edge angles and circumradii, but again, often only numerically.
I should point out that this is not necessarily a criticism of these wonderful books, since each book had its own purpose. What I found, though, was that there was really no book out there which took a more mathematically sophisticated viewpoint at an intermediate level.
So I decided that if I wanted to know more about polyhedra — that is, know the exact metrical data associated with polyhedra, not just numerical approximations — I needed to do some work on my own.
I used two approaches — coordinates and linear algebra, and spherical trigonometry. In both cases, I wanted precise results — so typically, this meant knowing exact values for the cosines of dihedral and edges angles, for example. When you know the cosine of an angle, you know the angle.
Why the cosine? The sine has the disadvantage of being ambiguous, since many dihedral angles of polyhedra are obtuse — so you need more information than just the sine of the angle. Using the tangent involved the troublesome case of 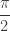
For my geometry course, I focused on spherical trigonometry — recall that I did not want linear algebra as a prerequisite for the course so that it would be accessible to a broader student demographic. But I still wanted to keep the mathematical rigor — use spherical trigonometry to calculate exact values of the cosines of relevant angles.
To give you an idea of what’s involved, let’s calculate the dihedral angle of a dodecahedron — that is, the angle between any two pentagonal faces of a regular dodecahedron.

To use spherical trigonometry (see a previous post on spherical geometry for a refresher), we imagine a small sphere centered at a vertex of the dodecahedron — it will carve out a spherical triangle, as shown below.
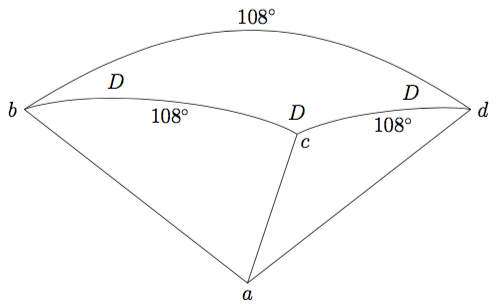
Here, a is a vertex of the dodecahedron, and points b, c, and d are the points where the small sphere intersects the edges of the dodecahedron meeting at a. This creates a spherical triangle whose sides all have measure 108°, since the interior angles of a regular pentagon all have measure 108°.
The angles between the sides of the spherical triangle with vertices a, b, and c are the dihedral angles of the dodecahedron, whose measure we call D. We may apply the law of cosines for spherical triangles in order to find D (see the relevant Wikipedia page; in the textbook, spherical trigonometric formulas are discussed in detail):
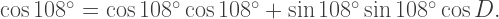
To find 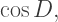
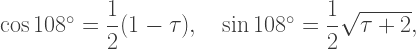
where 
Solving yields
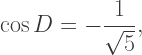
so that D is approximately 116.6°.
Now this is not the only way to find D; it is possible to find Cartesian coordinates for the vertices of the dodecahedron and use some linear algebra, for example. But using spherical trigonometry is straightforward and elegant — and is surprisingly versatile.
When I teach my polyhedra course, we use spherical trigonometry to find edge and dihedral angles of all the Platonic and Archimedean solids. Further, we use spherical trigonometry to design geodesic models, like the 4-frequency icosahedron shown here.

So the emphasis is on applying spherical trigonometry to the construction of physical models. In a typical two-lecture-per-week course, one lecture is always a hands-on laboratory, where we build a polyhedron or geodesic model we studied previously. We never build a model without knowing precisely how it is designed — we first understand the mathematics of the model, and then we build it. Included in the text is a week-by-week outline of how I’ve used the text in the classroom.
Now the classroom textbook is just Part I of the book. Part II is a bit more technical, and intended for the true polyhedral enthusiast. It turns out that spherical trigonometry is a powerful tool for studying polyhedra. In fact, the dihedral angles of all the uniform polyhedra may be calculated using spherical trigonometry — even the most complex snub polyhedra. However, it is sometimes necessary to solve sixth-degree polynomials in order to do so!
I thought to add Part II to the volume as I had already done all the calculations some years ago. And, to my knowledge, the calculation of the dihedral angles of all the uniform polyhedra using spherical trigonometry has not been published before. So I hope to contribute something to the literature of classical polyhedral geometry by publishing this book, in a way that someone with a modest mathematical background can understand.
As I continue with the book project, I’ll post updates as I discover interesting geometrical tidbits along the way!




 find
find 
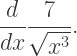
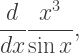

 at
at 
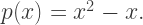
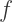 and
and  are differentiable functions. Find
are differentiable functions. Find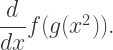


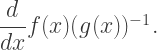
 is tangent to both
is tangent to both  and
and 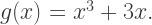 Find
Find 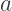 and
and 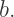


 by the cubic polynomial
by the cubic polynomial
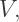
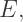 and
and 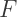 are the number of vertices, edges, and faces, respectively, on a convex polyhedron, then
are the number of vertices, edges, and faces, respectively, on a convex polyhedron, then
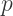 denote the number of sides on the regular polygons, and let
denote the number of sides on the regular polygons, and let  denote the number of polygons meeting at each vertex of the Platonic solid. (Those familiar with polyhedra will recognize these as the usual variables.)
denote the number of polygons meeting at each vertex of the Platonic solid. (Those familiar with polyhedra will recognize these as the usual variables.)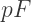 sides on all of the polygons.
sides on all of the polygons.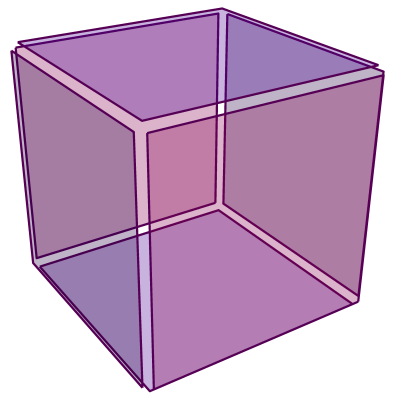
 also counts all of the sides on the polygons. Since we are counting the same thing in two different ways, we have
also counts all of the sides on the polygons. Since we are counting the same thing in two different ways, we have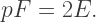
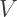 vertices on a Platonic Solid, and if
vertices on a Platonic Solid, and if  is the total number of vertices on all of the polygons. Again, having counted the same thing in two different ways, we have
is the total number of vertices on all of the polygons. Again, having counted the same thing in two different ways, we have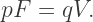

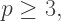 and since at least three polygons must come together at the vertex of a convex polyhedron, we must also have
and since at least three polygons must come together at the vertex of a convex polyhedron, we must also have 
 and
and 
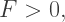 so that
so that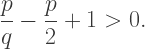
 and rearrange terms, giving
and rearrange terms, giving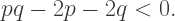
 to both sides so that the left-hand side factors nicely:
to both sides so that the left-hand side factors nicely: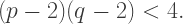
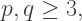 then
then 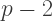 and
and 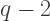 must both be integers at least
must both be integers at least 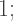 but since their product must be less than
but since their product must be less than 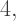 they can be at most
they can be at most 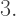
 or
or 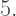
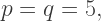 then
then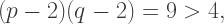
 and
and  we have the octahedron, since
we have the octahedron, since 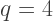 means that four triangles meet at each vertex.
means that four triangles meet at each vertex.
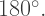 And the fact that similarity and congruence on the sphere are the same concept, unlike in Euclidean geometry. For example, if the angles in a Euclidean triangle are the same in pairs, the triangles are similar. But on a sphere, if the angles of two spherical triangles measured the same in pairs, they would necessarily have to be congruent.
And the fact that similarity and congruence on the sphere are the same concept, unlike in Euclidean geometry. For example, if the angles in a Euclidean triangle are the same in pairs, the triangles are similar. But on a sphere, if the angles of two spherical triangles measured the same in pairs, they would necessarily have to be congruent.
 dimensions is of the form
dimensions is of the form
 and calculating a simple ratio reveals that you’ve got
and calculating a simple ratio reveals that you’ve got  of your potato left.
of your potato left. of your potato left, where
of your potato left, where  so after you’ve peeled your potato, you’ve only got about one-third of it left!
so after you’ve peeled your potato, you’ve only got about one-third of it left!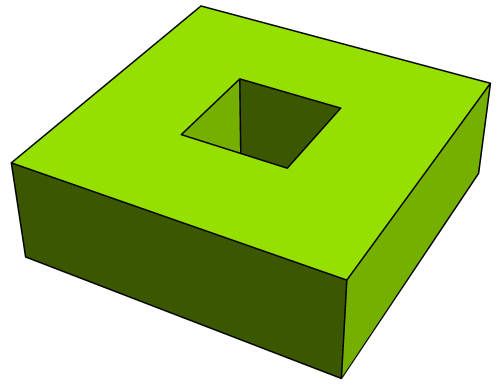
 formula. This is not really exciting in and of itself, but in the next lecture, I plan to find the volume of a regular tetrahedron by inscribing it in the usual way in the cube by joining alternate vertices.
formula. This is not really exciting in and of itself, but in the next lecture, I plan to find the volume of a regular tetrahedron by inscribing it in the usual way in the cube by joining alternate vertices. What I’m referring to, specifically, is that the number of vertices on a three-dimensional simplex is half the number of vertices of a three-dimensional hypercube.
What I’m referring to, specifically, is that the number of vertices on a three-dimensional simplex is half the number of vertices of a three-dimensional hypercube.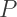 represent the number of pentagons on the buckyball, and
represent the number of pentagons on the buckyball, and  represent the number of hexagons. Then the number of vertices
represent the number of hexagons. Then the number of vertices 
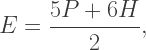
 since the faces are just the pentagons and hexagons. Substitute these expressions into Euler’s formula
since the faces are just the pentagons and hexagons. Substitute these expressions into Euler’s formula