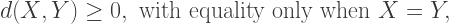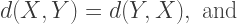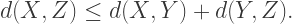I’ll talk about LaTeX in this installment of On Coding — and my next one, too. There is so much to say, I realized I couldn’t say it all in just one blog post.
LaTeX is a markup language, like HTML, but its purpose is completely different. TeX was invented when its creator, Donald Knuth, thought the galley proofs for one of his computer science textbooks looked so awful, he thought that something should be done about it. This was in the late 70’s. TeX was initially released in 1978; in 1985, Leslie Lamport released LaTeX, which is a more user-friendly version of TeX. This Wikipedia article has a more complete history if you’re interested.
Basically, LaTeX makes math look great. Here’s a formula taken from the paper Nick and I submitted to Bridges 2017 recently.
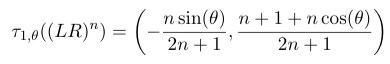
It’s perfectly formatted, all the symbols and spacing nicely balanced. Without mentioning any names, try producing that same formula in some other well-known word-processing environment, and you’ll find out it doesn’t even come close to looking that good.
Before I go into more detail about all my favorite LaTeX features, I’d like to explain how it works. Typically, you download some TeX GUI — I use TeXworks at home. The environment looks like this:

On the left-hand side is the LaTeX markup, and on the right-hand side is a previewer which shows you how your compiled text would look as a pdf document. Just type in your text, compile, view, repeat. Much like HTML.
There are many things I like about LaTeX, and it’s hard to rank them in any particular order. Although first — and foremost — mathematical formulas look fantastic.
A close second is the fact that it’s fast. By that, I mean that because a markup language it text-based, there’s no mouse involved. I’m a very fast typist, which means I can type LaTeX markup almost as fast as I can type ordinary text. If you’ve ever hard to typeset a formula by means of drop-down menus, you know exactly what I mean.
The third feature is closely related to the second: it’s intuitive. For example, to get the trigonometric formula

you would type
$$\tan\frac{\theta}{2}=\frac{\sin\theta}{1+\cos\theta}$$.
All commands in LaTeX are preceded by a backslash (“\”), so you can always distinguish them from text. And if you look at the text, you can almost figure out the formula just from reading the commands. It maps perfectly.
Most of LaTeX is that way — the commands describe what they do. For example,

is created using
$$x\rightarrow y$$.
Now you might be thinking that’s a lot to type for a simple formula — surely there must be a shorter way! First, there is. You can just define your own macro by saying
\def\ra{\rightarrow}
so you could just type
$$x\ra y$$.
This might be a good thing to do if you use a right arrow all the time. But secondly, if you just use it occasionally, it’s really quite easy to remember. When you want a right arrow, you just type “\rightarrow”. If you want a longer arrow which points in both directions, like

you just type
$$x\longleftrightarrow y$$.
Once you understand how the commands are named, it’s often easy to guess which one you’ll need just by thinking about it.
Next up, LaTeX makes your life a lot easier, especially when you’re working on big projects. There are a lot of ways this is done, so I’ll just mention one of my favorites — the “\label” command.

This equation (again from the Bridges paper) is typeset using the commands (broken up for reference):
- \begin{equation}
- \bigcup_{j\in{\mathbb Z}}{\bf R}^{2j}_{\theta}\,C_{r,\theta}^n={\bf R}^{n\,\rm{mod}\,2}_{\theta}\bigcup_{j\in{\mathbb Z}}{\bf R}^{2j}_{\theta}\,C_{1/r,\theta}^n
- \label{theorem1}
- \end{equation}
The equation (described by (2)) is sandwiched between a begin/end block ((1) and (4)). But the key command is the “\label” command on line (3). When you want to refer to this equation in LaTeX, you don’t use text like “equation (5)”, you say “equation (\ref{theorem1})”.
The \label command assigns the number of the equation — in this case, 5 — to the label “theorem1”. So when you use the “\ref” command (stands for “reference,” naturally), LaTeX will look for the number assigned to “theorem1”.
This might not seem like a big deal at first. But as you work on a paper, you’re always deleting equations, adding them, or moving them around. By assigning them labels, any references you make to equations in your text are automatically updated when you make changes.
And while we’re on the subject of equations — of course an extremely important topic when thinking about writing mathematics — there is also the “\nonumber” command, as well. Before you end the equation, you migh add a \nonumber tag, as in
\begin{equation}<stuff>\label{eq1}\nonumber\end{equation}.
Why would you label an equation for easy reference, and then not even put the number next to the equation? It is good mathematical style to only number equations that are referenced in the text. If you just show them once and don’t refer to them later, they don’t need a number.
But as you rewrite a proof, for example, you might find you no longer need to reference a particular equation, and so you don’t need the number any more. So rather than having to format it as not an equation (deleting the begin/end block), you just add the \nonumber tag. It’s a lot easier.
So what I do is label every equation as I write, and then when I have a final draft, I just go through and unnumber all those equations which I never end up referencing. It’s so nice.
I know I went on a bit about equations, but similar conveniences are available for figures, tables, article sections, book chapters, bibliographic entries, etc. You never have to remember a number. Ever.
And yes, there’s more…. Stay tuned for the next On Coding installment, where I’ll give you more reasons for wanting to learn LaTeX!










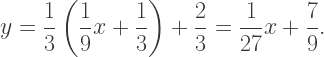


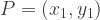 and
and 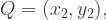 the distance between them is defined to be
the distance between them is defined to be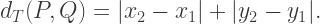
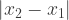 is how far your taxicab would have to drive in an east-west direction, and
is how far your taxicab would have to drive in an east-west direction, and  is how far your taxicab would have to drive in a north-south direction. Absolute values are needed: the distances
is how far your taxicab would have to drive in a north-south direction. Absolute values are needed: the distances  and
and 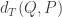 should be positive and equal to each other.
should be positive and equal to each other.
 to mean the Euclidean distance. In Euclidean geometry, the only way this inequality can actually be an equality is if Y is on the line segment whose endpoints are X and Z — and no other way. But as we’ve just seen,
to mean the Euclidean distance. In Euclidean geometry, the only way this inequality can actually be an equality is if Y is on the line segment whose endpoints are X and Z — and no other way. But as we’ve just seen,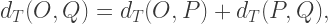
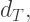 the geometry changes. In a very fundamental way, as you see.
the geometry changes. In a very fundamental way, as you see.