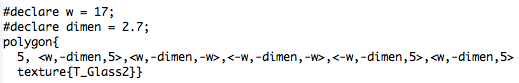I made a decision last week to abandon using Sage (now called CoCalc) as a platform in my Mathematics and Digital Art class. It was not an easy decision to make, as there are some nice features (which I’ll get to in a moment). But now any effective use of Sage comes with a cost — the free version uses servers, and you are given this pleasant message: “This project runs on a free server (which may be unavailable during peak hours)….”
This means that to guarantee access to CoCalc, you need a subscription. It would not be prohibitively expensive for my class — but as I am committed to being open source, I am reluctant to continue putting sample code on my web page which requires a cost in order to use. Yes, there is the free version — as long as the server is available….
When I asked my students last semester about moving exclusively to Processing, they responded with comments to the effect that using Sage was a gentle introduction to coding, and that I should stick with it. I fully intended to do this, and got started preparing for the first few days of classes. I opened my Sage worksheet, and waited for it to load. And waited….
That’s when I began thinking — I did have experiences last year where the class virtually came to a halt because Sage was too slow. It’s a problem I no longer wanted to have.
So now I’m going to Processing right from the beginning. But why was I reluctant in the past?
The issue is that of user space versus screen space. (See Making Movies with Processing I for a discussion of these concepts.) With Sage, students could work in user space — the usual Cartesian coordinate system. And the programming was particularly easy, since to create geometrical objects, all you needed to do was specify the vertices of a polygon.
I felt this issue was important. Recall the success I felt students achieved by being able to alter the geometry of the rectangles in the assignment about Josef Albers and color. (See the post on Josef Albers and Interaction of Color for a refresher on the Albers assignment.)

Most students experimented significantly with the geometry, so I wanted to make that feature readily accessible. It was easy in Sage, the essential code looking something like this:

What is happening here is that the base piece is essentially an array of rectangles within unit squares, with lower-left corners of the squares at coordinates (i, j). So it was easy for students to alter the polygons rendered by using graph paper to sketch some other polygon, approximate its coordinates, and then enter these coordinates into the nested loops.
Then Sage rendered whatever image you created on the screen, automatically sizing the image for you.
But here is the problem: Processing doesn’t render images this way. When you specify a polygon, the coordinates must be in screen space, whose units are pixels. The pedagogical issue is this: jumping into screen space right at the beginning of the semester, when we’re just learning about colors and hex codes, is just too big a leap. I want the first assignment to focus on getting used to coding and thinking about color, not changing coordinate systems.
Moreover, creating polygons in Processing involves methods — object-oriented programming. Another leap for students brand new to coding.
The solution? I had to create a function in Processing which essentially mimicked the “polygon” function used in Sage. In addition, I wanted to make the editing process easy for my students, since they needed to input more information this time.

In Processing — in addition to the number or rows and columns — students must specify the screen size and the length of the sides of the squares, both in pixels. The margins — xoffset and yoffset — are automatically calculated.
Here is the structure of the revised nested for loops:

Of course there are many more function calls in the loops — stroke weights, additional fill colors and polygons, etc. But it looks very similar to the loop formerly written in Sage — even a bit simpler, since I moved the translations to arguments (instead of needing to include them in each vertex coordinate) and moved all the output routines to the “myshape” function.
Again, the reason for this is that creating arbitrary shapes involves object-oriented concepts. See this Processing documentation page for more details.
Here is what the myshape function looks like:

The structure is not complicated. Start by invoking “createShape,” and then use the “beginShape” method. Adding vertices to a shape involves using the “vertex” method, once for each vertex. This seems a bit cumbersome to me; I am new to using shapes in Processing, so I’m hoping to learn more. I had been able to get by with just creating points, lines, rectangles, and circles so far — but that doesn’t give students as much room to be creative as including arbitrary shapes does.
I should point out that shapes can have subshapes (children) and other various attributes. There is also a “fill” method for shapes, but I have students use the fill function call in the for loop to avoid having too many arguments to myshape. I also think it helps in understanding the logical structure of Processing — the order in which functions calls are invoked matters. So you first set your fill color, then when you specify the vertices of your polygon, the most recently defined fill color is used. That subtlety would get lost if I absorbed the fill into the myshape function.
As in previous semesters, I’ll let you know how it goes! Like last semester, I’ll give updates approximately monthly, since the content was specified in detail in the first semester of the course (see Section L. of 100 Posts! for a complete listing of posts about the Mathematics and Digital Art course).
Throughout the semester, I’ll be continuously moving code from Sage to Processing. It might not always warrant a post, but if I come across something interesting, I’ll certainly let you know!