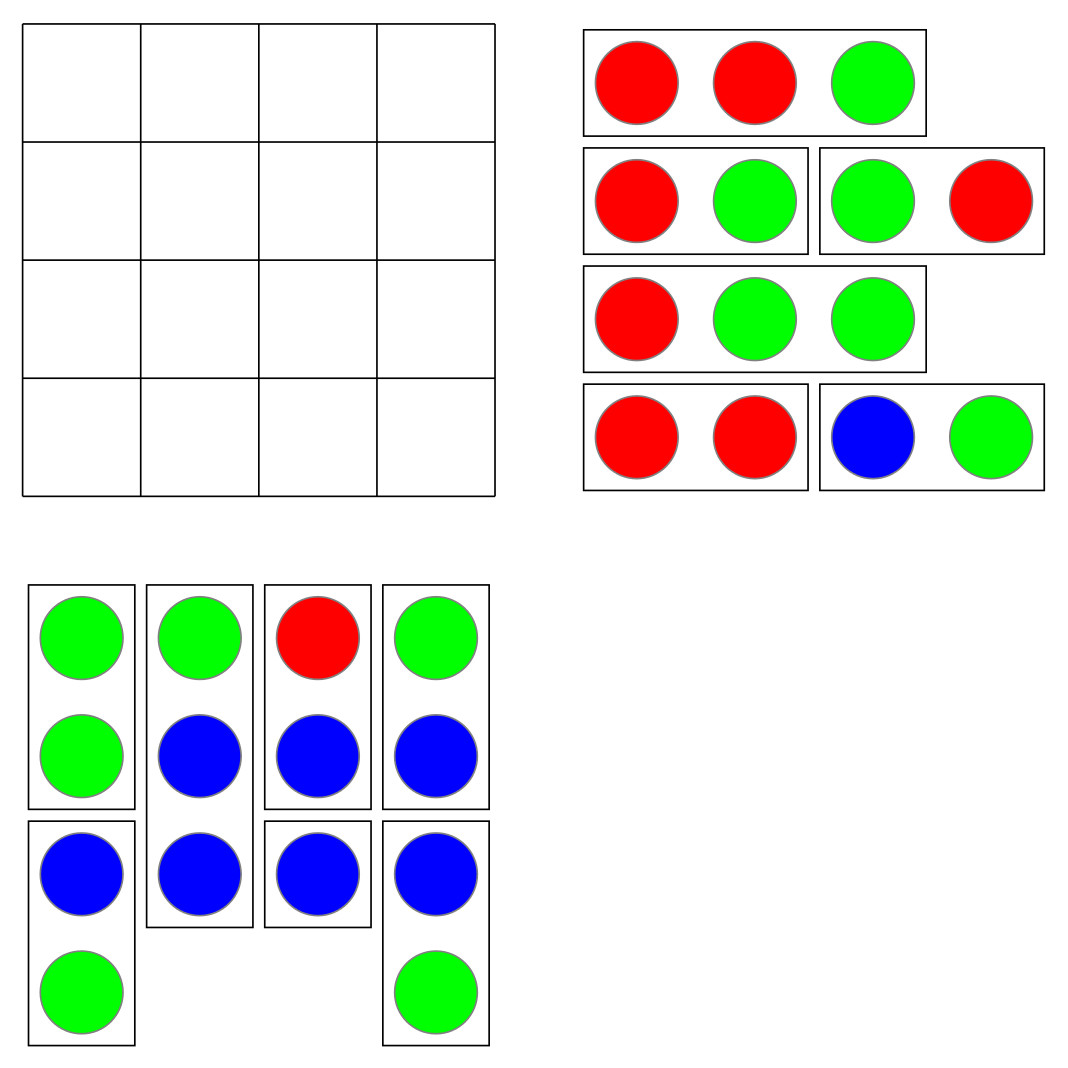
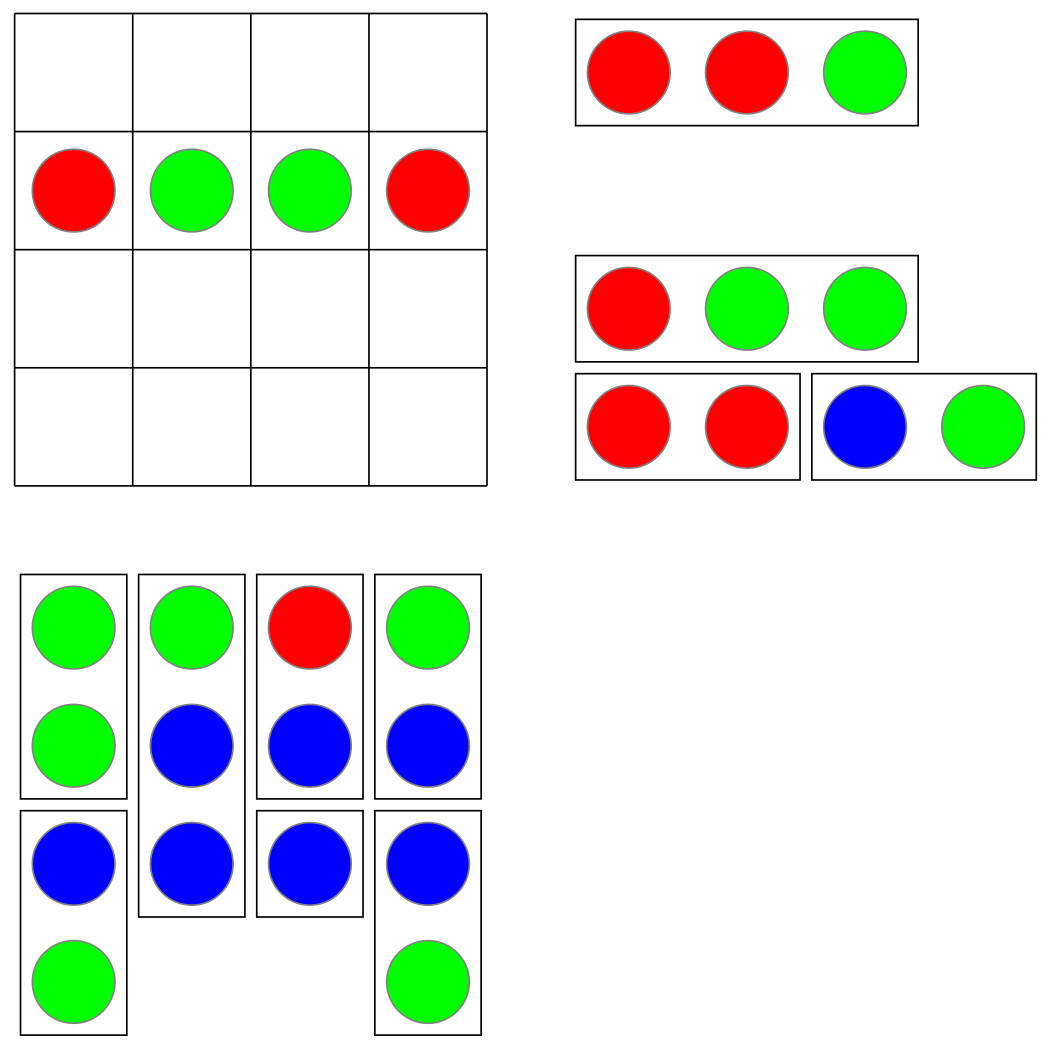
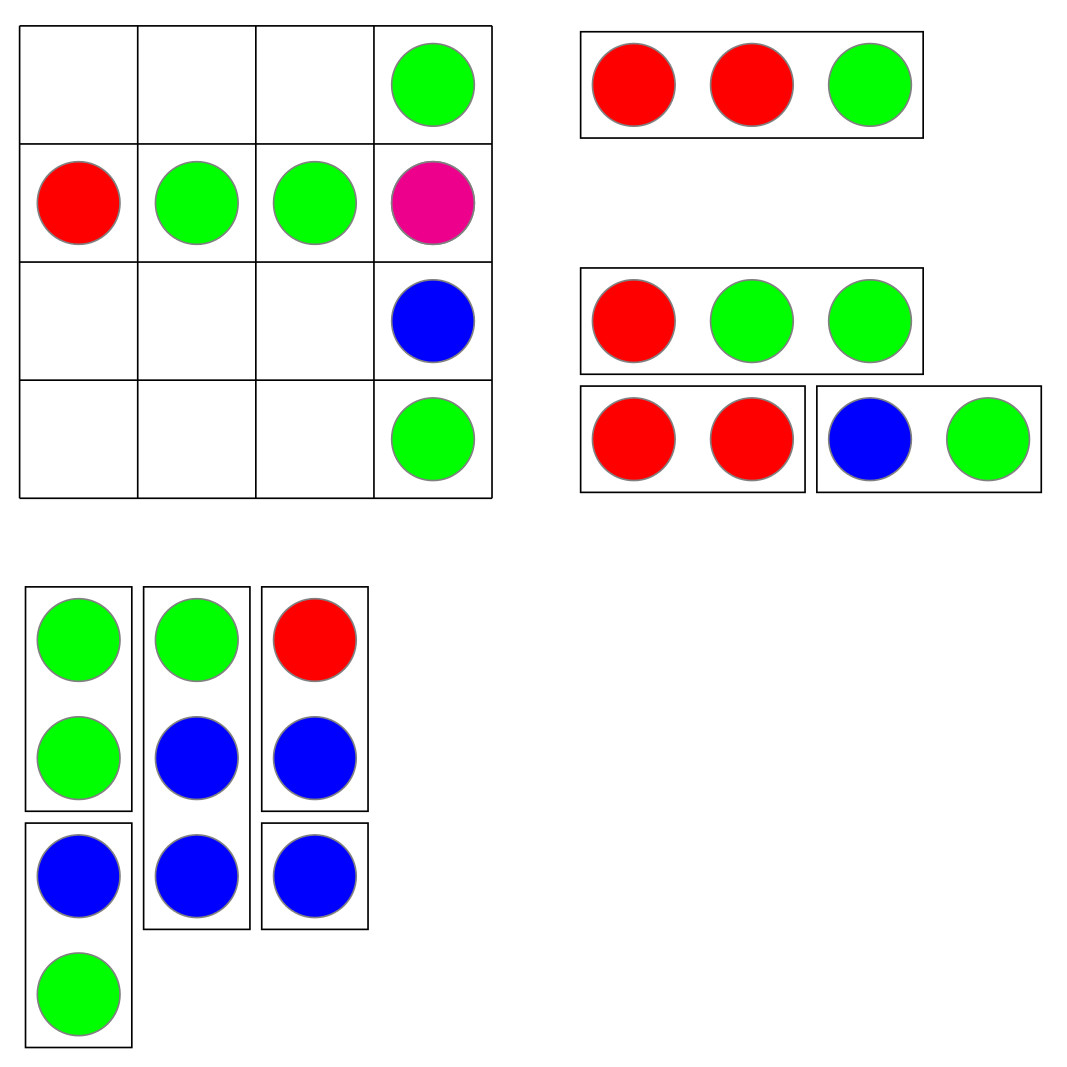
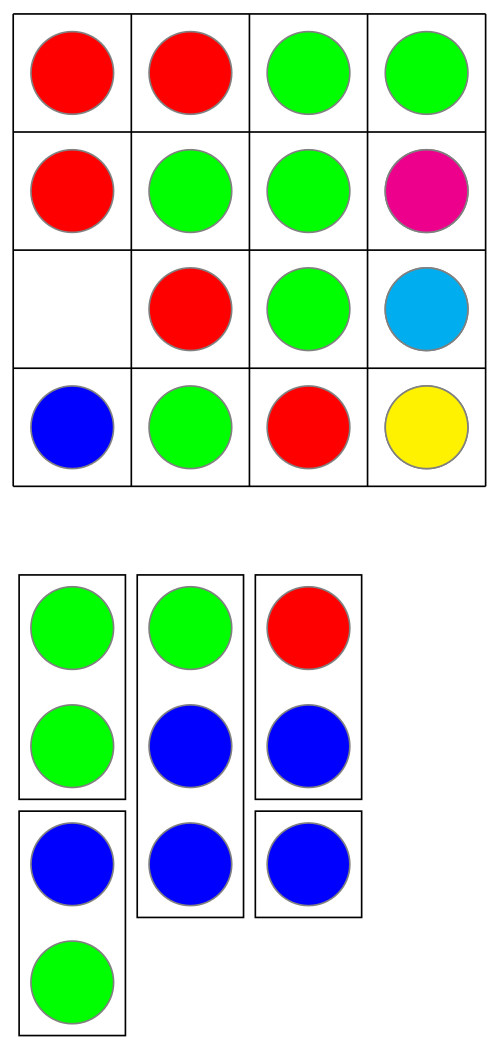
A friend and colleague recently suggested (thanks, Sanza!) writing a meta-post about creating a Math Blog, and I thought now might be a good time. It’s been about four months since my first post, and I’ve found my stride (metaphorically, at least).
What motivated me to write a blog? I realized I’d written a lot over the years in the form of puzzles and problems that I wanted to share. But I had trouble thinking of a good venue — except perhaps writing a book — and it suddenly dawned on me that a blog might be the way to go.
As I mused upon the idea further, I began thinking about my artwork as well, and wanting to share a lot of those ideas, too. I wanted the blog to be accessible — which doesn’t mean devoid of some interesting mathematics — as well as fairly novel. There are good blogs which cull stuff from all over the internet, but I didn’t want to write one of those. I thought that a creativity thread would be just what I wanted — to show mathematics as a creative endeavor. And having taught for many years, I realized that this was one aspect of mathematics lost on most students at any level. (As discussed in two recent posts.)
And so a blog was born. Or conceived, I should say. I settled on an audience of advanced middle school students to undergrads — but I was aiming at a fairly sophisticated student. One who isn’t afraid of mathematics or programming, and is willing to dive into something new.
Now I’ve written a lot over the past several years, including a few books, so I thought that the writing would be fairly manageable. But knowing that projects are often more involved than originally imagined, I decided to draft my first ten blog posts and get some feedback before I even started. This was in August, before the semester began, and I thought it a prudent move so I didn’t get stuck in a content bind right away.
That work definitely paid off — and it made me think a lot about what I wanted to write before I launched the blog. I wanted a nice blend of art, puzzles, teaching ideas, and geometry; drafting some initial posts helped me to organize those thoughts.
I decided early on to incorporate programming, for a few reasons. I would have to say that the computer is perhaps the most important tools I use as a mathematician. I think nothing of writing a Mathematica routine to test out a conjecture say, a million times, before I dive into looking for a proof. And as an artist, well, the blog speaks amply to that point.
But I had just started learning Python in January of this year for a course I was teaching, and using it on the Sage platform. I felt it was important that anything I did with programming should be accessible and open source, and Sage fit the bill perfectly — just click on the link! Nothing to download or install.
But more importantly, I wanted to use programming to help illustrate the creative process — and encourage others to be similarly creative. Making a puzzle, designing some artwork — not mysterious endeavors, but realizable projects made easier with the help of a few lines of code.
At that point, I had the basic setup in mind, and went for the first post! You might have noticed (those of you following from the beginning), that the “Read More” sections have disappeared. I originally thought to divide the content into two sections, so the reader might digest it in smaller chunks.
But with the help of the statistics gathered by WordPress, I noticed the following phenomenon. When I began making movies and included one in the main body and one in the “Read More” section, the latter was hardly ever played. So the chunking plan seemed only to succeed in having readers look at only half of my posts…..
So at that point, I decided to eliminate the “Read More” sections — and therefore also the idea of including a puzzle at the end of each essay for those who weren’t particularly interested in such things. They’d have to endure….
I settled, then, upon writing one-section posts of about 1000 words. This is long enough to say something interesting, but not too long to lose a dedicated reader.
I’ve received some good feedback so far, but the readership is still fairly small. Now that I’m accumulating enough content, one of my next steps is to reach out to some colleagues and perhaps former students to help me publicize my blog. More and more schools are teaching Python, and I think some of my posts on art and programming would make interesting projects for students taking an introductory programming course.
I’d also like to do some guest blogging — having other friends and colleagues describe their creative processes. I haven’t decided exactly what form that will take yet, but that doesn’t need to be decided immediately.
One neat side effect is that I’ve got to meet some interesting people online through their comments, and not all are from the US. I’m surprised by the geographic diversity of viewers — it’s fascinating how the internet transcends national boundaries. I’m hoping to meet more people as the blog evolves.
Is it worth it? So far, I’d say yes. I’ve had many interesting conversations as a result of blog posts, and I enjoy putting my thoughts down on paper (metaphorically, that is). Aside from the time invested (which is not insignificant), the only other cost involved was upgrading WordPress so there wouldn’t be any ads on my blog — I was quite surprised when I test posted and was informed that there might be ads!
For the would-be blogger, then, no good advice — a blog is a very personal endeavor, and sometimes you’ve just got to jump in and give it a go. But this is my story — and I’m sticking to it! Good luck if you’re willing to give it a try.
Word count is now 1,011, meaning it’s time to go. You get pretty good after a while at putting your thoughts into 1000-word chunks….
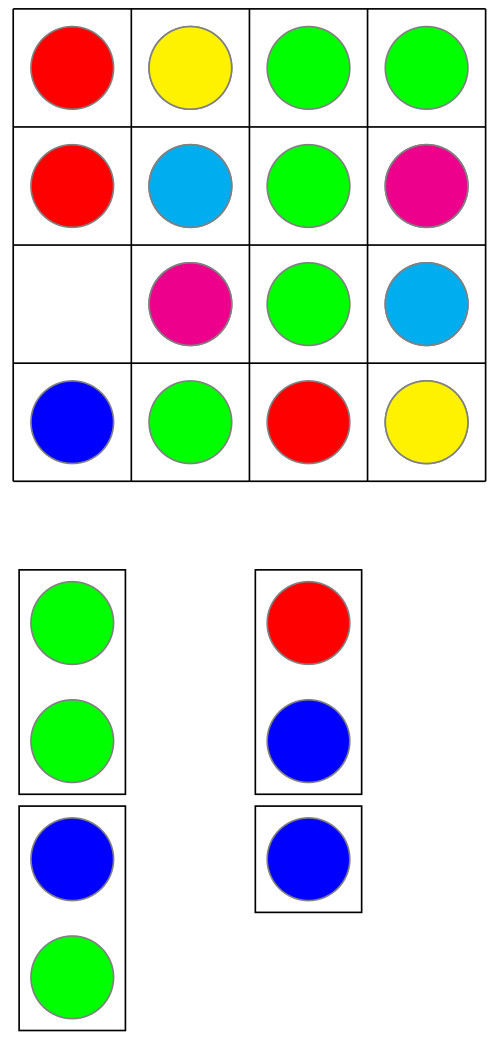
 ), or 3XX, where the first X represents multiplication, and the second X the number 10. What an I or X represents in a row may not the same as what it represents in the corresponding column. And as usual, no number can begin with a “0.” Happy solving!
), or 3XX, where the first X represents multiplication, and the second X the number 10. What an I or X represents in a row may not the same as what it represents in the corresponding column. And as usual, no number can begin with a “0.” Happy solving!
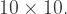
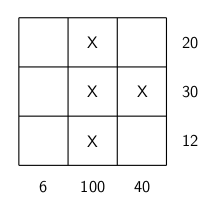
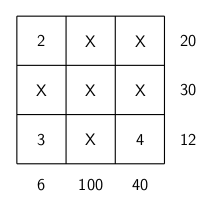
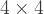 puzzle below, I used 13 since it might either be written as a Roman numeral XIII, or a multiplication like 1X13. Having some entries end in 0 means a multiplication by 10, but that might be represented by 10 or X.
puzzle below, I used 13 since it might either be written as a Roman numeral XIII, or a multiplication like 1X13. Having some entries end in 0 means a multiplication by 10, but that might be represented by 10 or X.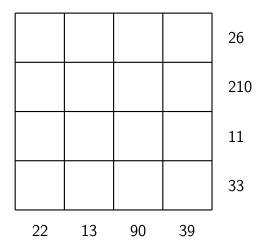
 puzzle.
puzzle.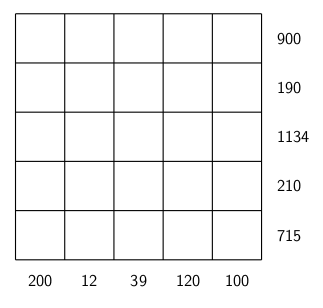

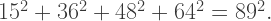
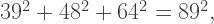
 (which is just a multiple of the Pythagorean triple
(which is just a multiple of the Pythagorean triple 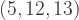 ) to obtain the possibility of a four-to-one dissection described above.
) to obtain the possibility of a four-to-one dissection described above. unit squares and reassemble!
unit squares and reassemble!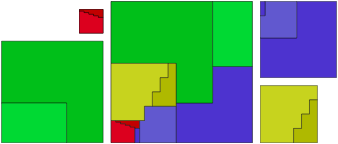
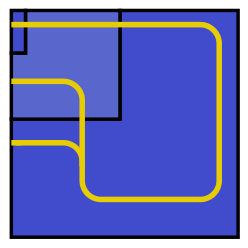

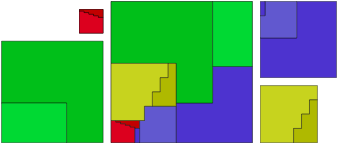


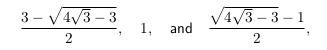 and these are some of the easier calculations! I won’t say more about that here — but you can read all about this dissection and many others in Greg’s book.
and these are some of the easier calculations! I won’t say more about that here — but you can read all about this dissection and many others in Greg’s book.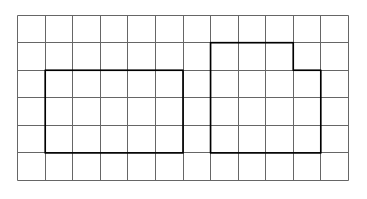 This seems like an easy puzzle to solve, as shown below.
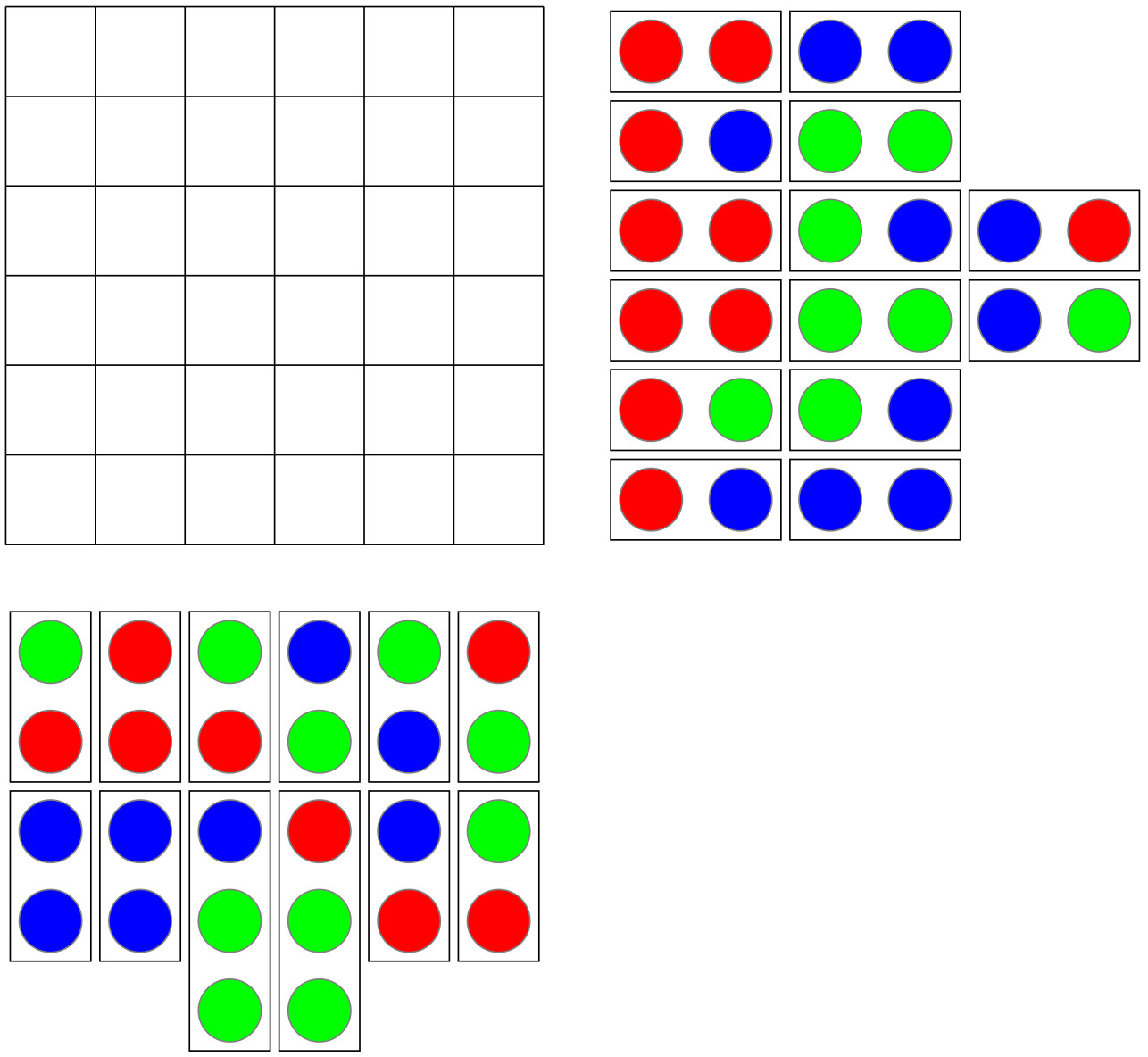
This seems like an easy puzzle to solve, as shown below.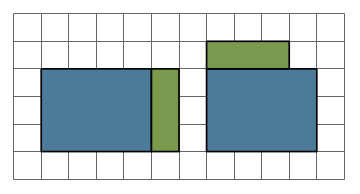 So yes, only two pieces are necessary — but one had to be rotated. Here is the question: can this puzzle be solved with just two pieces, but with neither piece rotated?
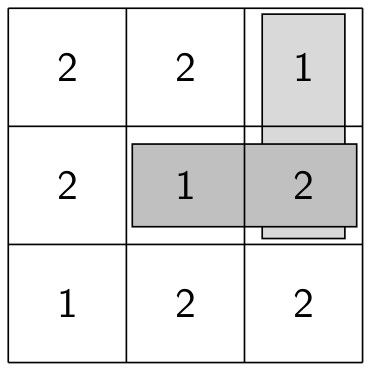
So yes, only two pieces are necessary — but one had to be rotated. Here is the question: can this puzzle be solved with just two pieces, but with neither piece rotated?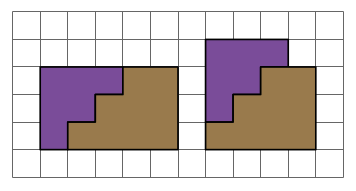 This is a solution technique commonly used in Dissections Plane & Fancy. Why bother? In the world of geometric dissections (and it is a growing universe, surely, as any internet search will show), finding a minimum number of pieces is the primary objective. But of all solutions with this minimum number of pieces, “nicer” solutions require rotating the fewest number of pieces. And rotating none at all is — in an aesthetic sense — “best.” It is also preferable not to turn pieces over, although sometimes this cannot be avoided for minimal solutions.
This is a solution technique commonly used in Dissections Plane & Fancy. Why bother? In the world of geometric dissections (and it is a growing universe, surely, as any internet search will show), finding a minimum number of pieces is the primary objective. But of all solutions with this minimum number of pieces, “nicer” solutions require rotating the fewest number of pieces. And rotating none at all is — in an aesthetic sense — “best.” It is also preferable not to turn pieces over, although sometimes this cannot be avoided for minimal solutions. It is important to note that the octagons here are not regular. A quick glance through Dissections Plane & Fancy will reveal that dissections involving regular polygons are generally rather difficult (as the initial triangle-to-square example amply shows).
It is important to note that the octagons here are not regular. A quick glance through Dissections Plane & Fancy will reveal that dissections involving regular polygons are generally rather difficult (as the initial triangle-to-square example amply shows).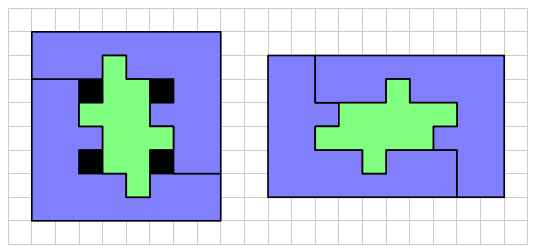
 I’ll leave you with two puzzles to think about. Of course, you can just make up your own. If you come with anything interesting, feel free to comment!
I’ll leave you with two puzzles to think about. Of course, you can just make up your own. If you come with anything interesting, feel free to comment!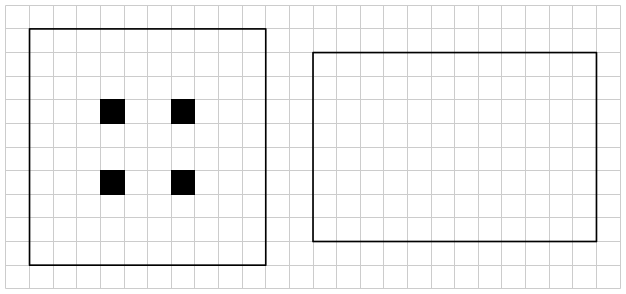



 So when
So when  we subtract
we subtract 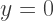 randomness to each color. But when
randomness to each color. But when  we subtract a random number between
we subtract a random number between  and
and 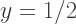 from each of the RGB values. Finally, at the very top, we’re subtracting a random number between
from each of the RGB values. Finally, at the very top, we’re subtracting a random number between  from each RGB value. Recall that if an RGB value would ever fall below
from each RGB value. Recall that if an RGB value would ever fall below 
 so subtracting the randomly generated number pushes the sky blue toward black. If we added instead, this would push the sky blue toward white. In fact, you can push the sky blue toward any color you want, but that’s a little too involved for today’s post.
so subtracting the randomly generated number pushes the sky blue toward black. If we added instead, this would push the sky blue toward white. In fact, you can push the sky blue toward any color you want, but that’s a little too involved for today’s post.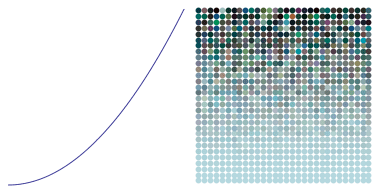
 for each value of
for each value of 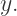 In other words, at a level of
In other words, at a level of 
 for the quadratic gradient. This is approximately the same color change you see in the linear gradient between
for the quadratic gradient. This is approximately the same color change you see in the linear gradient between 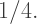 Why does this happen? Because when you square numbers less than
Why does this happen? Because when you square numbers less than  they get smaller. So smaller numbers will introduce less randomness in a quadratic gradient than they will in a linear gradient.
they get smaller. So smaller numbers will introduce less randomness in a quadratic gradient than they will in a linear gradient. ), the color changes more gradually at the bottom. But if we use an exponent less than
), the color changes more gradually at the bottom. But if we use an exponent less than 
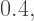 so that for a particular
so that for a particular 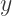 value, a random number between
value, a random number between  is subtracted from each RGB value. Note how quickly the color changes from the sky blue at the bottom toward very dark colors at the top.
is subtracted from each RGB value. Note how quickly the color changes from the sky blue at the bottom toward very dark colors at the top. square. It’s actually easier to think in terms of integer variables “width” and “height” (after all, there is no reason our image needs to be square). In this case, we use “j” as the height parameter, since it is more usual to use variables like “i” and “j” for integers. So “j/height” would correspond to
square. It’s actually easier to think in terms of integer variables “width” and “height” (after all, there is no reason our image needs to be square). In this case, we use “j” as the height parameter, since it is more usual to use variables like “i” and “j” for integers. So “j/height” would correspond to  and values near the bottom of the image correspond to
and values near the bottom of the image correspond to  I’ll leave it to you to explore all the other details of the Python code.
I’ll leave it to you to explore all the other details of the Python code.