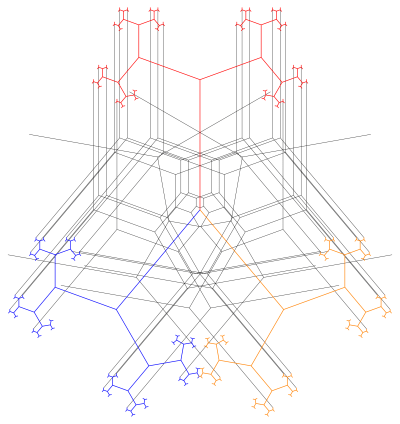
Last week I talked about working with binary trees whose branching ratio is 1 or greater. The difficulty with having a branching ratio larger than one is that the tree keeps growing, getting larger and larger with each iteration.
But when you work with software like Mathematica, for example, and you create such a tree, you can specify the size of the displayed image in screen size.


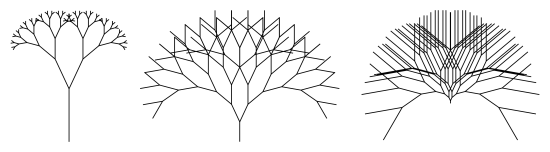
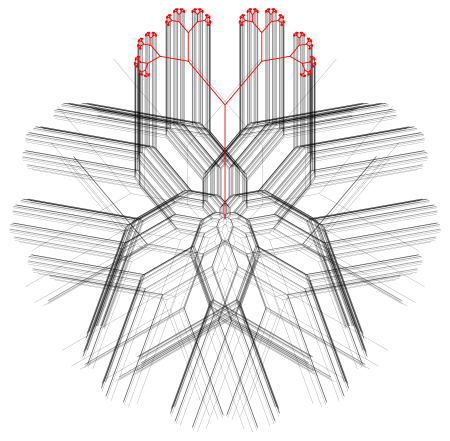
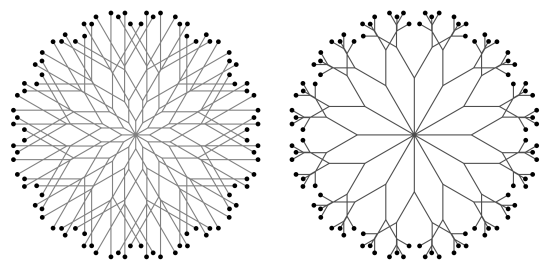
So the trees above both have branching ratio 2 and branching angle of 70°. The left image is drawn to a depth of 7, and the right image is drawn to a depth of 12. I specified that both images be drawn the same size in Mathematica.
But even though they are visually the same size, if you start with a trunk 1 unit in length, the left image is about 200 units wide, while the second is 6000 units wide!
So this prompted us to look at scaling back trees with large branching ratios. In other words, as trees kept getting larger, scale them back even more. You saw why this was important last week: if the scale isn’t right, when you overlap trees with r less than one on top of the reciprocal tree with branching ratio 1/r, the leaves of the trees won’t overlap. The scale has to be just right.
So what should these scale factors be? This is such an interesting story about collaboration and creativity — and how new ideas are generated — that I want to share it with you.
For your usual binary tree with branching ratio less than one, you don’t have to scale at all. The tree remains bounded, which is easy to prove using convergent geometric series.
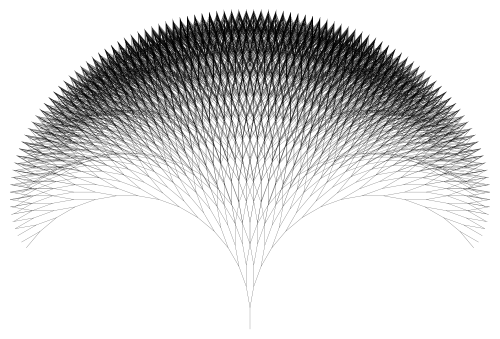
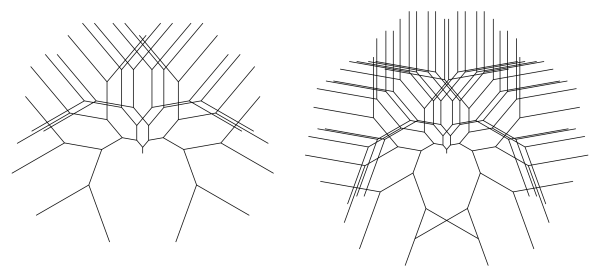
What about the case when r is exactly 1, as shown in the above figure? At depth n, if you start with a trunk of length 1, the path from the base of the trunk to the leaf is a path of exactly n + 1 segments of length 1, and so can’t be any longer than n + 1 in length. As the branching angle gets closer to 0°, you do approach this bound of n + 1. So we thought that scaling back by a factor of n + 1 would keep the tree bounded in the case when r is 1.
What about the case when r > 1? Let’s consider the case when r = 2 as an example. The segments in any path are of length 1, 2, 4, 8, 16, etc., getting longer each time by a power of 2. Going to a depth of n, the total length is proportional to 

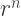
So we knew how to keep the trees bounded, and started including these scaling factors when drawing our images. But there were two issues. First, we still had to do some fudging when drawing trees together with their reciprocal trees. We could still create very appealing images, but we couldn’t use the scale factor on its own.
And second — and perhaps more importantly — Nick had been doing extensive exploration on his computer generating binary trees. Right now, we had three different cases for scaling factors, depending on whether r < 1, r = 1, or r > 1. But in Nick’s experience, when he moved continuously through values of r less than 1 to values of r greater than one, the transition looked very smooth to him. There didn’t seem to be any “jump” when passing through r = 1, as happened with the scale factors we had at the moment.
I wasn’t too bothered by it, though. There are lots of instances in mathematics where 1 is some sort of boundary point. Take geometric series, for example. Or perhaps there is another boundary point which separates three fundamentally different types of solutions. For example, consider the quadratic equation
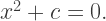
The three fundamentally different solution sets correspond to c < 0, c = 0, and c > 0. There is a common example from differential equations, too, though I won’t go into that here. Suffice it to say, this type of trichotomy occurs rather frequently.
I tried explaining this to Nick, but he just wouldn’t budge. He had looked at so many binary trees, his intuition led him to firmly believe there just had to be a way to unify these scale factors.
I can still remember the afternoon — the moment — when I saw it. It was truly beautiful, and I’ll share it in just a moment. But my point is this: I was so used to seeing trichotomies in mathematics, I was just willing to live with these three scale factors. But Nick wasn’t. He was tenacious, and just insisted that there was further digging to do.
Don’t ask me to explain how I came up with it. It was like that feeling when you just were holding on to some small thing, and now you couldn’t find it. But you never left the room, so it just had to be there. So you just kept looking, not giving up until you found it.
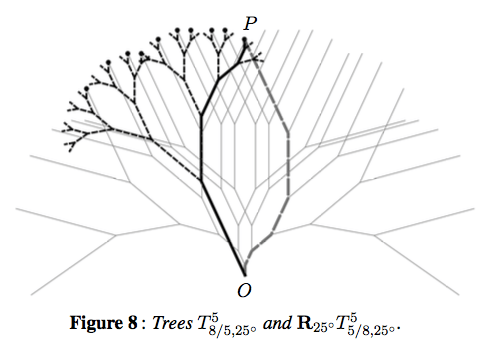
And there is was: if the branching ratio was r and you were iterating to a depth of n, you scaled back by a factor of
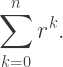
This took care of all three cases at once! When r < 1, this sum is bounded (think geometric series), so the boundedness of the tree isn’t affected. When r = 1, you just get n + 1 — the same scaling factor we looked at before! And when r > 1, this sum is large enough to scale back your tree so it’s bounded.
Not only that, this scale factor made proving the Dual Tree Theorem so nice. The scaling factors for a tree with r < 1 and its reciprocal tree with branching ratio 1/r matched perfectly. No need to fudge!
This isn’t the place to go into all the mathematics, but I’d be happy to share a copy of our paper if you’re interested. We go into a lot more detail than I ever could in a blog post.
This is how mathematics happens, incidentally. It isn’t just a matter of finding a right answer, or just solving an equation. It’s a give-and-take, an exploration, a discovery here and there, tenacity, persistence. A living, breathing endeavor.
But the saga isn’t over yet…. There is a lot more to say about binary trees. I’ll do just that in my next installment of Imagifractalous!
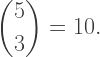









 is a p-adic valuation and p is prime, it’s not hard to show that
is a p-adic valuation and p is prime, it’s not hard to show that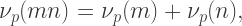
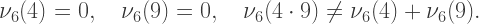




 and I’m specifying the denominator of that fraction.
and I’m specifying the denominator of that fraction.
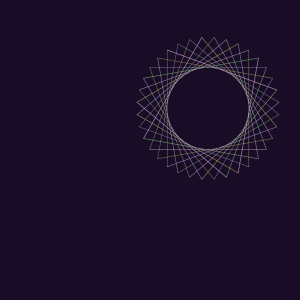
 Even when they do close, some appealing results are obtained by cropping the images.
Even when they do close, some appealing results are obtained by cropping the images.
 F
F  F
F  but that does not preclude the possibility of there being others, of course.
but that does not preclude the possibility of there being others, of course.
 with opacity 1.
with opacity 1. Dividing these by 255 to convert to values between 0 and 1, I get
Dividing these by 255 to convert to values between 0 and 1, I get  I actually used RGB values of
I actually used RGB values of  to create the image, so the eyedropper tool did its job….
to create the image, so the eyedropper tool did its job…. and the opacity
and the opacity  Recall the formula from last week for the result of looking through a transparent color:
Recall the formula from last week for the result of looking through a transparent color:
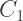 is the color of the pink square, and
is the color of the pink square, and  is the color of the purple square. So we get the equation
is the color of the purple square. So we get the equation
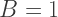 (go back and reread this argument if you forgot). The equations for the Red and Green components are
(go back and reread this argument if you forgot). The equations for the Red and Green components are


 so the pink square can be transparent as long as
so the pink square can be transparent as long as

 while the point Y corresponds to
while the point Y corresponds to  Note that while the possible points in RG space lie on a line segment (it is easy to see from the above formulas that
Note that while the possible points in RG space lie on a line segment (it is easy to see from the above formulas that  ), the points on the line segment do not vary linearly with
), the points on the line segment do not vary linearly with 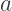 since the
since the 
 denote the color of the pink square underneath, which will be
denote the color of the pink square underneath, which will be  Using the opacity formula, we obtain the equation
Using the opacity formula, we obtain the equation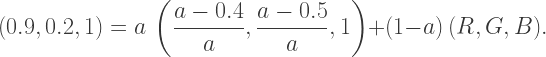


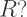 Since the opacity must be between 0 and 1 — in other words,
Since the opacity must be between 0 and 1 — in other words,  — the numerator of this expression will always be greater than the denominator. This means that the Red color value would have to be greater than 1, which we know is not possible!
— the numerator of this expression will always be greater than the denominator. This means that the Red color value would have to be greater than 1, which we know is not possible!
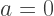 means that the color is completely transparent, so it doesn’t affect the image at all, while a value of
means that the color is completely transparent, so it doesn’t affect the image at all, while a value of 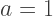 means the color is completely opaque, meaning you can’t see through it at all.
means the color is completely opaque, meaning you can’t see through it at all.

 the apparent or observed color is then
the apparent or observed color is then

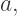 our linear interpolation formula would give an apparent color of
our linear interpolation formula would give an apparent color of

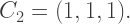
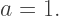
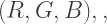 we get
we get
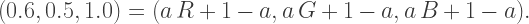

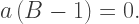
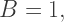 which makes sense since if we’re interpolating between
which makes sense since if we’re interpolating between 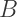 and 1, the only way to get a result of 1.0 would be if
and 1, the only way to get a result of 1.0 would be if 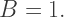



 and
and 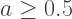
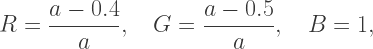
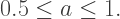 This is illustrated graphically below, where the solid line segment represents all possible colors for the square.
This is illustrated graphically below, where the solid line segment represents all possible colors for the square.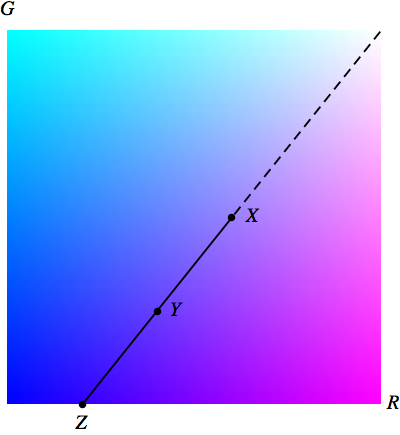
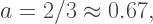 we obtain the point Y with coordinates (0.4, 0.25) in RG space. This means the purple square could be obtained using RGB values of (0.4, 0.25, 1.0) and opacity
we obtain the point Y with coordinates (0.4, 0.25) in RG space. This means the purple square could be obtained using RGB values of (0.4, 0.25, 1.0) and opacity 
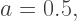 we obtain the point Z with coordinates (0.2, 0) in RG space. This means the purple square could be obtained using RGB values of (0.2, 0, 1.0) and opacity 0.5.
we obtain the point Z with coordinates (0.2, 0) in RG space. This means the purple square could be obtained using RGB values of (0.2, 0, 1.0) and opacity 0.5.






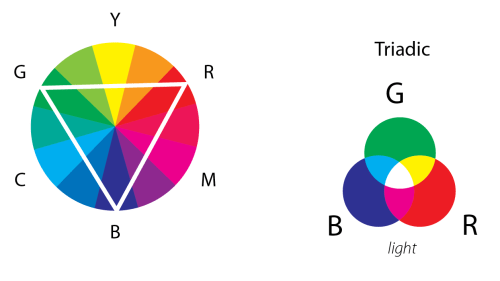
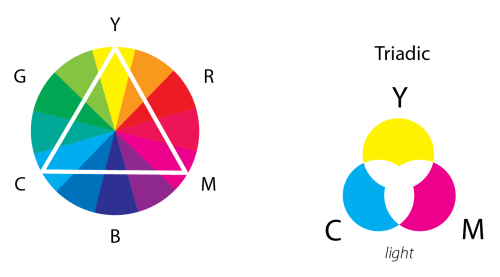
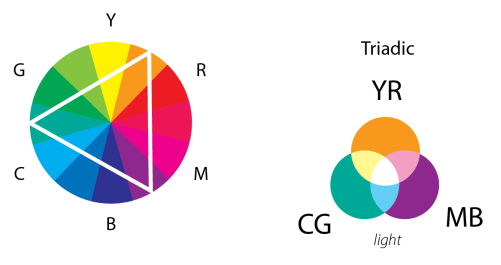
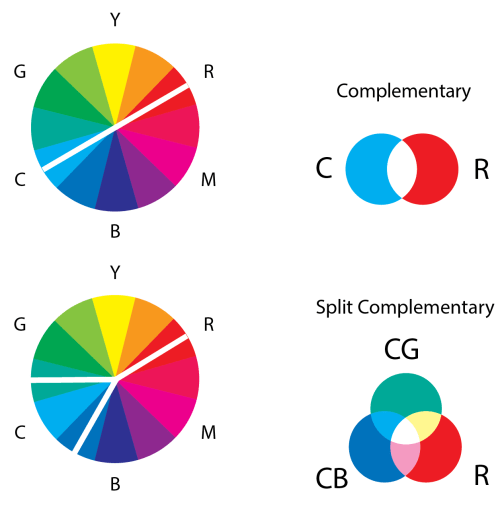
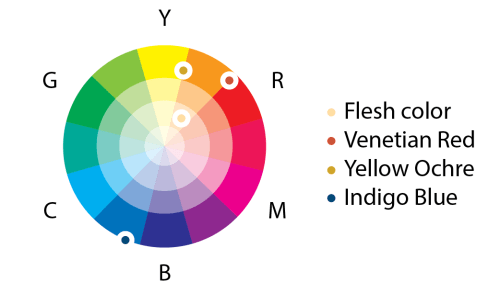
 This lovely wheel is often called the Yurmby wheel because it’s somewhat more pronounceable then YRMBCG(Y). The benefit of the Yurmby is that the primary of one system is the secondary of the other. With the RGB system,
This lovely wheel is often called the Yurmby wheel because it’s somewhat more pronounceable then YRMBCG(Y). The benefit of the Yurmby is that the primary of one system is the secondary of the other. With the RGB system,