It’s hard to believe it’s been four weeks already! Recall that we ended Week 2 with work on an Evaporation piece. We’ll see examples of student work after a brief recap of Weeks 3 and 4 (Days 6–10).
In the past two weeks, we focused on affine transformations and their use in creating fractals with iterated function systems. This was not intended to be a deep discussion of linear algebra, but a practical one — how affine transformations reflect the geomtetry of fractal images.

Days 6 and 7 were an introduction to the geometry of affine transformations. I like to emphasize the geometry first, so I worked to find a way to simply and unambiguously describe an affine transformation geometrically.
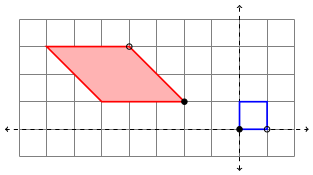
The blue square represents the unit square, and the red parallelogram the transformed square. The filled-in/open black circles on the parallelogram represent how (0,0) and (1,0) are transformed, respectively. Additionally, the pink fill in the parallelogram represents that fact that there is a flip (that is, the determinant of the linear part of the transformation is negative). Strictly speaking, this coloring isn’t necessary, but I think it helps.
We then worked on writing the affine transformation in the form
![T\left(\begin{matrix}x\\y\end{matrix}\right)=\left[\begin{matrix}a&b\\c&d\end{matrix}\right]\left(\begin{matrix}x\\y\end{matrix}\right)+\left(\begin{matrix}e\\f\end{matrix}\right)](https://s0.wp.com/latex.php?latex=T%5Cleft%28%5Cbegin%7Bmatrix%7Dx%5C%5Cy%5Cend%7Bmatrix%7D%5Cright%29%3D%5Cleft%5B%5Cbegin%7Bmatrix%7Da%26b%5C%5Cc%26d%5Cend%7Bmatrix%7D%5Cright%5D%5Cleft%28%5Cbegin%7Bmatrix%7Dx%5C%5Cy%5Cend%7Bmatrix%7D%5Cright%29%2B%5Cleft%28%5Cbegin%7Bmatrix%7De%5C%5Cf%5Cend%7Bmatrix%7D%5Cright%29&bg=ffffff&fg=333333&s=2&c=20201002)
We did this in the usual way, where the columns of the matrix represent where the unit basis vectors are transformed, and the vector added at the end is the translation from the origin. These can all be read from the diagram, so that the picture above describes the affine transformation
![T\left(\begin{matrix}x\\y\end{matrix}\right)=\left[\begin{matrix}-2&-3\\2&0\end{matrix}\right]\left(\begin{matrix}x\\y\end{matrix}\right)+\left(\begin{matrix}-2\\1\end{matrix}\right).](https://s0.wp.com/latex.php?latex=T%5Cleft%28%5Cbegin%7Bmatrix%7Dx%5C%5Cy%5Cend%7Bmatrix%7D%5Cright%29%3D%5Cleft%5B%5Cbegin%7Bmatrix%7D-2%26-3%5C%5C2%260%5Cend%7Bmatrix%7D%5Cright%5D%5Cleft%28%5Cbegin%7Bmatrix%7Dx%5C%5Cy%5Cend%7Bmatrix%7D%5Cright%29%2B%5Cleft%28%5Cbegin%7Bmatrix%7D-2%5C%5C1%5Cend%7Bmatrix%7D%5Cright%29.&bg=ffffff&fg=333333&s=2&c=20201002)
To help in visualizing this in general, I also wrote a Sage worksheet which produces diagrams like the above picture given the parameters a—f. In addition, I showed how the vertices of the parallelogram may be found algebraically by using the transformation itself, so this meant we could look at affine transformations geometrically and algebraically, as well as with the Sage worksheet. (Recall that all worksheets/assignments may be found on the corresponding day on the course website. In addition, I have included the 
I explained several different types of affine transformations — translations, reflections, scalings, and shears. On Day 8, we saw how to write the affine transformations which describe the Sierpinski triangle, and students got to play with creating their own fractals using the accompanying Sage worksheet.
On Day 9, I took about half the class to go through three of my blog posts on iterated function systems. I emphasized the first spiral fractal discussed on Day035, paying particular attention to the rotation involved and matrix multiplication.
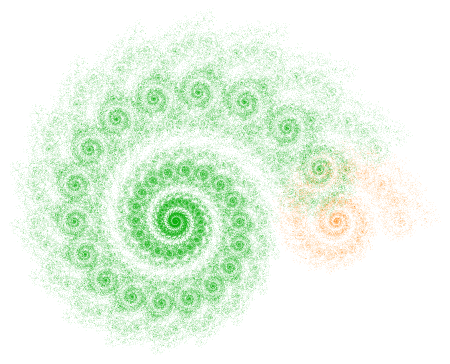
Most students weren’t familiar with trigonometry (recall the course has no prerequisites), so I just told them the formula for rotation matrices. We briefly discussed matrix multiplication as function composition. I gave them homework which involved some practice with the algebra of matrix multiplication.
On Day 10, we began with going over some previous homework, and then looked at what transformations were needed to producing the fractal below (as practice for their upcoming homework).
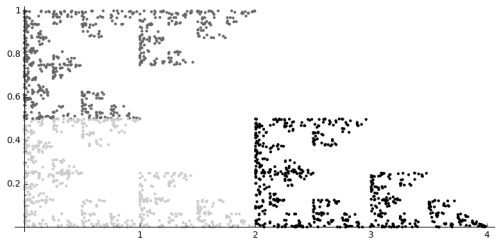
We then engaged in the following laboratory exercise: Create a fractal using two affine transformations. For the first, rotate by 45 degrees, then scale the x by 0.6 and the y by 0.4, and finally move to the right 1. For the second transformation, rotate 90 degrees clockwise, and then move up 1.
This was practice in going from a geometrical description to a fractal — they needed to perform the appropriate calculations, and then enter the data in the Sage worksheet and see if their fractal was correct (I gave them a link to the final image).
This turned out to be very challenging, as they were just getting familiar with rotations and matrix multiplication. So we’ll need to finish during the next class. I’ll also give them another similar lab exercise during the next class to make sure they’ve got it.
Last week’s digital art assignment was another success! Again, I was very pleased with how creative my students were. If you look back at the Sage worksheets, you’ll see that the class was working with color, texture, and color gradients (like my Evaporation piece).
One student created a texture with a lot of movement by keeping the circles separate and using a wide range of gray tones.

Maddie took advantage of the fact that the algorithm draws the circles in a particular order to create a scalloped texture. This happens when the circles are particularly large, since the circles are drawn in a linear fashion, creating successive overlap.

Another student also used this overlapping feature with a color gradient. He describes his piece as follows:
This piece is what I like to call “The Hedge” as it reminds me a lot of those tall square hedges that are in mansions. It’s as if the light is hitting the top of the hedge and dispersing down into the shadows and thickness of the leaves. I especially like the leafy effect the overlapping circles give.

Finally, Madison experimented with altering the dimensions of the grid to create a different feel.

She thought that making the image wider made the evaporation effect more pronounced.
These are just some examples of how students in my Mathematics and Digital Art course take ideas I give them and make them their own. They are always asking how they can incorporate one effect or another into their work, and Nick and I are glad to oblige by helping out with a little code.
As I strive to keep my posts a consistent length, I won’t be able to share all the images I’d like to this week. So I’ll be posting additional images on my Twitter feed, @cre8math. Follow along if you’d like to see more!





 where
where  — it isn’t exactly obvious if you’ve never done it before. Having Nick as my TA in the class really helped out — I was at the board, and he was at the computer drawing graphs of functions and varying the parameters in the routine to produce color gradients. We worked well together.
— it isn’t exactly obvious if you’ve never done it before. Having Nick as my TA in the class really helped out — I was at the board, and he was at the computer drawing graphs of functions and varying the parameters in the routine to produce color gradients. We worked well together.







 with opacity 1.
with opacity 1. Dividing these by 255 to convert to values between 0 and 1, I get
Dividing these by 255 to convert to values between 0 and 1, I get  I actually used RGB values of
I actually used RGB values of  to create the image, so the eyedropper tool did its job….
to create the image, so the eyedropper tool did its job….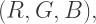 and the opacity
and the opacity  Recall the formula from last week for the result of looking through a transparent color:
Recall the formula from last week for the result of looking through a transparent color:
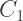 is the color of the pink square, and
is the color of the pink square, and  is the color of the purple square. So we get the equation
is the color of the purple square. So we get the equation
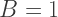 (go back and reread this argument if you forgot). The equations for the Red and Green components are
(go back and reread this argument if you forgot). The equations for the Red and Green components are


 so the pink square can be transparent as long as
so the pink square can be transparent as long as

 while the point Y corresponds to
while the point Y corresponds to  Note that while the possible points in RG space lie on a line segment (it is easy to see from the above formulas that
Note that while the possible points in RG space lie on a line segment (it is easy to see from the above formulas that  ), the points on the line segment do not vary linearly with
), the points on the line segment do not vary linearly with  since the
since the 
 denote the color of the pink square underneath, which will be
denote the color of the pink square underneath, which will be  Using the opacity formula, we obtain the equation
Using the opacity formula, we obtain the equation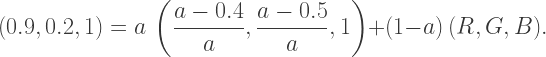


 Since the opacity must be between 0 and 1 — in other words,
Since the opacity must be between 0 and 1 — in other words,  — the numerator of this expression will always be greater than the denominator. This means that the Red color value would have to be greater than 1, which we know is not possible!
— the numerator of this expression will always be greater than the denominator. This means that the Red color value would have to be greater than 1, which we know is not possible!
 means that the color is completely transparent, so it doesn’t affect the image at all, while a value of
means that the color is completely transparent, so it doesn’t affect the image at all, while a value of  means the color is completely opaque, meaning you can’t see through it at all.
means the color is completely opaque, meaning you can’t see through it at all.

 the apparent or observed color is then
the apparent or observed color is then

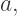 our linear interpolation formula would give an apparent color of
our linear interpolation formula would give an apparent color of

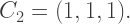
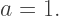
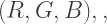 we get
we get
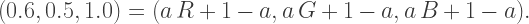

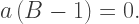
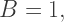 which makes sense since if we’re interpolating between
which makes sense since if we’re interpolating between 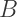 and 1, the only way to get a result of 1.0 would be if
and 1, the only way to get a result of 1.0 would be if 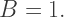



 and
and 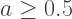
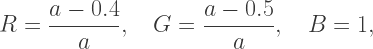
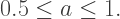 This is illustrated graphically below, where the solid line segment represents all possible colors for the square.
This is illustrated graphically below, where the solid line segment represents all possible colors for the square.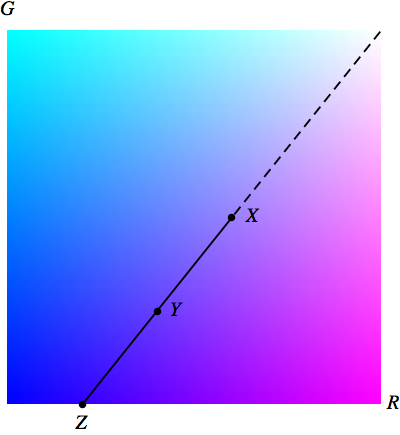
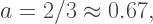 we obtain the point Y with coordinates (0.4, 0.25) in RG space. This means the purple square could be obtained using RGB values of (0.4, 0.25, 1.0) and opacity
we obtain the point Y with coordinates (0.4, 0.25) in RG space. This means the purple square could be obtained using RGB values of (0.4, 0.25, 1.0) and opacity 
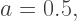 we obtain the point Z with coordinates (0.2, 0) in RG space. This means the purple square could be obtained using RGB values of (0.2, 0, 1.0) and opacity 0.5.
we obtain the point Z with coordinates (0.2, 0) in RG space. This means the purple square could be obtained using RGB values of (0.2, 0, 1.0) and opacity 0.5.






 This lovely wheel is often called the Yurmby wheel because it’s somewhat more pronounceable then YRMBCG(Y). The benefit of the Yurmby is that the primary of one system is the secondary of the other. With the RGB system,
This lovely wheel is often called the Yurmby wheel because it’s somewhat more pronounceable then YRMBCG(Y). The benefit of the Yurmby is that the primary of one system is the secondary of the other. With the RGB system,